Table des matières
Génération de textes avec aitextgen et GPT-2
Cette page est la suite de Générer du texte en python avec textgenrnn
Les chercheurs retardent la publication de leurs recherches car ils estiment que GPT2 a un potentiel « trop dangereux », étant donné que cette IA pourrait à terme servir à des actes mal intentionnées comme générer des avis négatifs ou positifs sur des produits, des spams, des textes complotistes, voire des fausses nouvelles. cf W
Bien sûr, tout a été publié, y compris le modèle big de 1.5 Go.
Why do we like Word2vec?
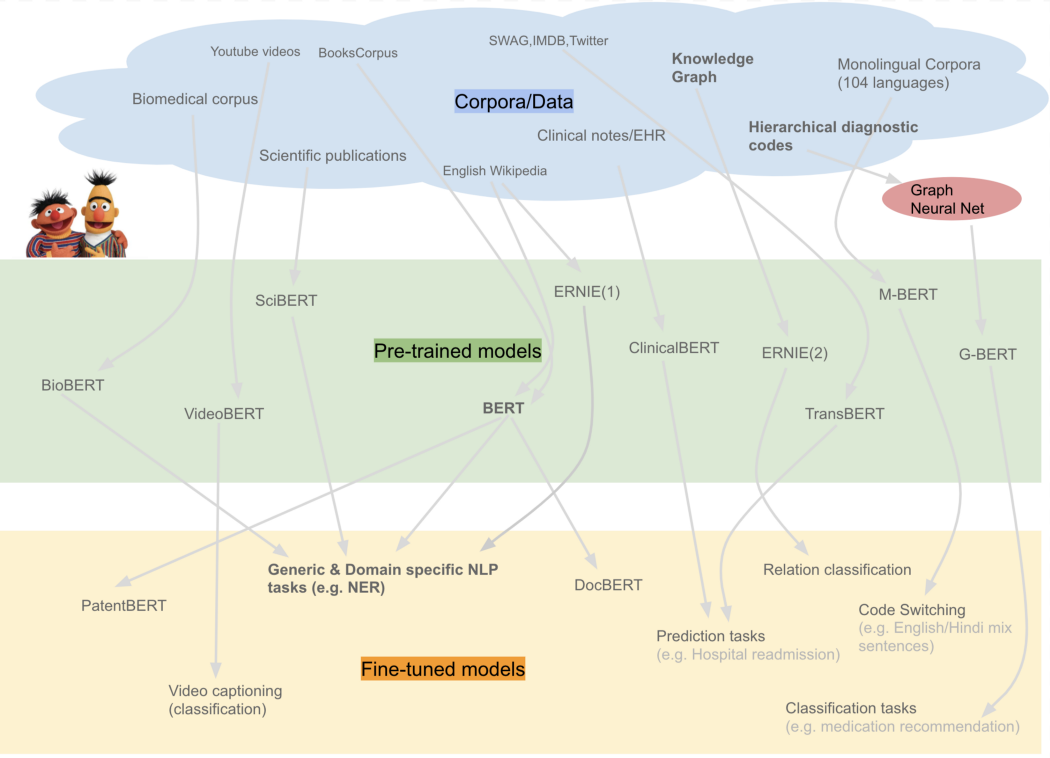
Ressources
aitextgen
- aitextgen de minimaxir sur github.com est une amélioration de textgenrnn de minimaxir sur github.com
- aitextgen est un outil Python robuste pour la formation et la génération d' intelligence artificielle basée sur du texte à l'aide de l' architecture GPT-2 d' OpenAI.
OpenAI
- OpenAI sur Wikipedia: OpenAI est une entreprise à « but lucratif plafonné » en intelligence artificielle, basée à San Francisco. L'objectif de cette société est de promouvoir et développer une intelligence artificielle à visage humain qui bénéficiera à toute l'humanité. OpenAI a mis au point une intelligence artificielle nommée GPT2 capable d'écrire des articles de presse et des œuvres de fiction. Reposant sur un générateur de texte qui assimile les mots reçus et détermine la suite la plus logique qu'elle retransmet dans le même style, elle s'avère particulièrement performante, à tel point qu'il est impossible de faire la différence avec un texte écrit par un être humain.
Les chercheurs retardent la publication de leurs recherches car ils estiment que GPT2 a un potentiel « trop dangereux », étant donné que cette IA pourrait à terme servir à des actes mal intentionnées comme générer des avis négatifs ou positifs sur des produits, des spams, des textes complotistes, voire des fausses nouvelles.
Controverse sur GPT-2
- La guerre des mots: comment les machines traitent le texte sur letemps.ch
Transformers
- Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0. Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides state-of-the-art general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, T5, CTRL…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over thousands of pretrained models in 100+ languages and deep interoperability between PyTorch & TensorFlow 2.0.
BERT
- BERT (traitement automatique du langage) En traitement automatique du langage naturel, BERT, acronyme de Bidirectional Encoder Representations from Transformers, est un modèle de langage (en) développé par Google en 2018. Cette méthode a permis d'améliorer significativement les algorithmes de traitement automatique de la langue.
CamemBERT
The CamemBERT model was proposed in CamemBERT: a Tasty French Language Model by Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah, and Benoît Sagot. It is based on Facebook’s RoBERTa model released in 2019. It is a model trained on 138GB of French text.
FlauBERT
The FlauBERT model was proposed in the paper FlauBERT: Unsupervised Language Model Pre-training for French by Hang Le et al. It’s a transformer pre-trained using a masked language modeling (MLM) objective (BERT-like).
Générateur de texte en ligne
Fables de La Fontaine avec un modèle entièrement créé
Suite de Avec des fables de La Fontaine
- training.py
from aitextgen import aitextgen from aitextgen.TokenDataset import TokenDataset from aitextgen.tokenizers import train_tokenizer from aitextgen.utils import GPT2ConfigCPU, GPT2Config from aitextgen import aitextgen def get_config(): return GPT2Config( vocab_size=20000, n_positions=1024, n_ctx=1024, n_embd=768, n_layer=12, n_head=12, bos_token_id=0, eos_token_id=0, max_length=1024, dropout=0.0 ) def training(): file_name = "./fables.txt" train_tokenizer(file_name, vocab_size=20000) vocab_file = "aitextgen-vocab.json" merges_file = "aitextgen-merges.txt" config = get_config() ai = aitextgen(vocab_file=vocab_file, merges_file=merges_file, config=config) data = TokenDataset(file_name, vocab_file=vocab_file, merges_file=merges_file, block_size=64) ai.train(data, batch_size=32, num_steps=60000) ai.generate(5, prompt="Le chien et le lion") training() """ essai 5 11,472 sets of tokens from ./fables.txt Loss: 0.094 — Avg: 0.093 """
- testing.py
from aitextgen import aitextgen from aitextgen.utils import GPT2Config class AiTextGen: def __init__(self): """Charge le gpt2 model de /aitextgen si existe, sinon le télécharge dans /aitextgen.""" self.prompt = "Romeo: " self.config = self.get_config() print("Config chargée.") print(" soit:\n", self.config) print("Création de aitextgen():") ai = aitextgen() print("Done.") self.vocab_file = "aitextgen-vocab.json" self.merges_file = "aitextgen-merges.txt" print("Chargement du modèle pytorch ...") self.ai = aitextgen(model="./trained_model/pytorch_model.bin", vocab_file=self.vocab_file, merges_file=self.merges_file, config=self.config) def get_config(self): return GPT2Config( vocab_size=20000, n_positions=1024, n_ctx=1024, n_embd=768, n_layer=12, n_head=12, bos_token_id=0, eos_token_id=0, max_length=1024, dropout=0.0 ) def get_irc_response(self, prompt, len_max, temp): if isinstance(prompt, str): resp = self.ai.generate(n=1, prompt=prompt, max_length=len_max, temperature=temp, return_as_list=True) return resp def interactif(self): while 1: try: prompt = input("Entrer un début de phrase:\n") except: prompt = "Ne jouer pas à ce petit jeu !" if isinstance(prompt, str) and len(prompt) > 4: resp = self.ai.generate(n=1, prompt=prompt, max_length=100, temperature=0.8, return_as_list=True) print(f"\n\nLa Fontaine n'a pas écrit:\n{resp[0]}\n\n") else: print("Raté") if __name__ == "__main__": atg = AiTextGen() atg.interactif()
Configuration
config = GPT2Config(vocab_size=20000, n_positions=1024, n_ctx=1024, n_embd=768, n_layer=12, n_head=12, bos_token_id=0, eos_token_id=0, max_length=1024, dropout=0.0 ) print(config) """ GPT2Config {"activation_function": "gelu_new", "attn_pdrop": 0.1, "bos_token_id": 0, "dropout": 0.0, "embd_pdrop": 0.1, "eos_token_id": 0, "initializer_range": 0.02, "layer_norm_epsilon": 1e-05, "max_length": 1024, "model_type": "gpt2", "n_ctx": 1024, "n_embd": 768, "n_head": 12, "n_layer": 12, "n_positions": 1024, "resid_pdrop": 0.1, "summary_activation": null, "summary_first_dropout": 0.1, "summary_proj_to_labels": true, "summary_type": "cls_index", "summary_use_proj": true, "vocab_size": 20000} """ ai = aitextgen(model="./trained_model/pytorch_model.bin", vocab_file=vocab_file, merges_file=merges_file, config=config) ai.generate(n=1, prompt=prompt, max_length=100, temperature=0.8, return_as_list=True)
Mails de La Labomedia
Configuration
def get_config(): return GPT2Config( vocab_size=20000, n_positions=1024, n_ctx=1024, n_embd=768, n_layer=12, n_head=12, bos_token_id=0, eos_token_id=0, max_length=1024, dropout=0.0 ) data = TokenDataset(file_name, vocab_file=vocab_file, merges_file=merges_file, block_size=64) ai.train(data, batch_size=32, num_steps=150000)
Les datas sont trop pourries, le résultat est très médiocre !
Des textes dans le domaine public du Projet Gutemberg
Free eBooks - Project Gutenberg
Extrait de Projet Gutenberg sur Wikipedia.
Le projet Gutenberg est une bibliothèque de versions électroniques libres de livres physiquement existants. Les textes fournis sont essentiellement du domaine public, soit parce qu'ils n'ont jamais été sujets à des droits d'auteur soit parce que ces derniers sont expirés. Le projet fut lancé par Michael Hart en 1971 et nommé en hommage à l'imprimeur allemand du XVe siècle Johannes Gutenberg.
Ce site n'autorise pas les robots, toutes les oeuvres a été téléchargées sur bouquineux.com au format epub.
Conversion de *.epub vers *.txt avec ebook-convert, puis regroupement de tous les textes dans un seul fichier, en séparant chaque œuvre par '\n\n<|endoftext|>\n\n'
Les fichiers non nettoyés font 300 Mo, et nettoyés font 280 Mo.
Nettoyage des datas
Les sauts de lignes, les sommaires … doivent être nettoyés: avec clean_txt.py
Le plus grand nettoyage est fait avec une détection de langue:
from langdetect import detect_langs je garde la ligne si langue.lang == 'fr' and langue.prob > 0.4:
Cela supprime les textes en anglais, en particulier les licences, les chiffres romains …
Le nettoyage des datas est très important, ce n'est pas drôle, il faut vérifier le résultat obtenu en tapant au hasard dans le texte, ça prend un temps fou …
La génération de texte est une représentation fidèle du texte d'apprentissage: par exemple si il y a beaucoup de saut de ligne, le texte généré aura aussi plein de saut de ligne.
Training
OOM = Out Of Memory
Finetuning the 355M GPT-2 model or larger on a GPU will cause the GPU to go OOM, even 16 GB VRAM GPUs
- Le fichier d'apprentissage a été coupé pour faire 112 Mo.
- vocab_size = 40 000
- batch_size = 48, valeur maxi possible avec 6 Go de Ram GPU (1060 GTX)
- Ram CPU = 16 Go, Swap=64 Go, valeur totale de l'occupation mémoire = 27 Go au moment de l'encodage du texte
Efficacité au bout de 144 heures:

Fables de La Fontaine avec la config de bouquineux
Avec la configuration de bouquineux et vocab=40000
 Remarque: Les Fables ont environ 13000 tokens, le vocab devrait se limiter à 14000 !
Remarque: Les Fables ont environ 13000 tokens, le vocab devrait se limiter à 14000 !
Testing pas mal mais quand même bourré d'erreur !
A partir du model tf_gpt2="124M" et vocab = 5000
- vocab_size=5000
- Apprentissage très rapide
- texte générés comme les précédents
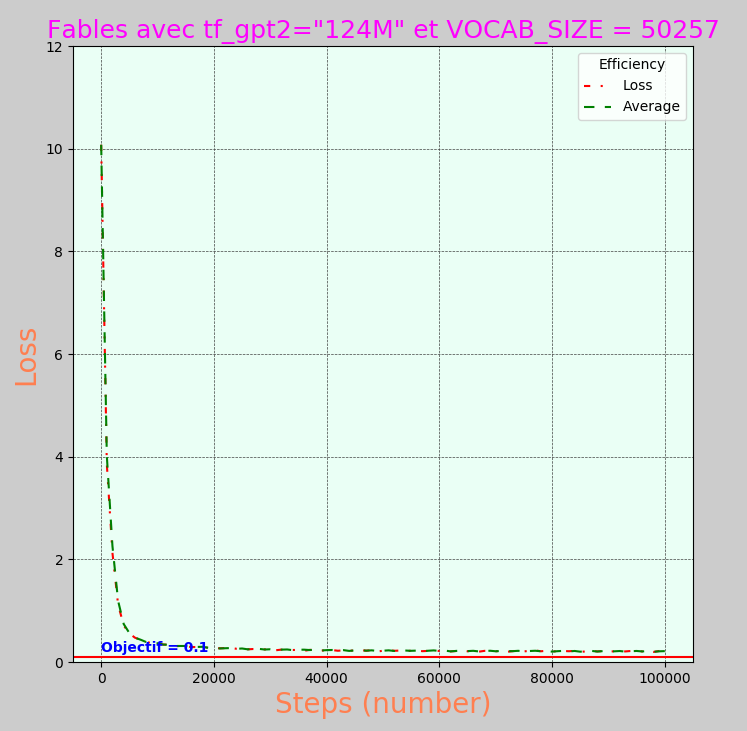
Fables de La Fontaine à partir du model tf_gpt2="124M" et vocab = 50275
C'est le meilleur générateur de texte, avec un apprentissage de 16 heures !
tf_gpt2=“124M” à une taille de 50275, il faut conserver cette valeur !
Affinage du model existant tf_gpt2="124M"
La ligne:
ai = aitextgen(tf_gpt2="124M")
va télécharger automatiquement le model.
Le training va affiner ce model. C'est un model construit sur un texte anglais, et pourtant cela va générer du texte français.
Shot de l'apprentissage
Pendant le trainning, les test de generate() retourne de l'anglais découpé en petit bout !

Courbe de loss
J'aimerais bien savoir à quoi ça correspond, j'ai peur que ce soit un simple calcul pas du tout représentatif!
Testing
 Le résultat comporte peu de mots mal construits, inexistants en français. Par contre, il n'y a aucun sens au texte, c'est mieux que du Nostradamus, mais c'est quasi de l'astrologie.
Le résultat comporte peu de mots mal construits, inexistants en français. Par contre, il n'y a aucun sens au texte, c'est mieux que du Nostradamus, mais c'est quasi de l'astrologie.
Développement à suivre
Construire sur le gros model de 1.5 Go !